Parsing a Text Column with Python


I recently had a project where I scraped salary data from Glassdoor. Some data cleaning was needed on the scraped data to prepare it for use in further analysis. One of the tasks involved having to parse the data in a column indicating location of company. This write-up is a walk-through of what I did.
The code below is what I ran initially to get new columns of city and state.
| df['City'] = df['Location'].apply(lambda x: x.split(', ')[0]) | |
| df['State'] = df['Location'].apply(lambda x: x.split(', ')[1]) | |
| df[['Company', 'Location', 'City']].head() |
In running it, I got an IndexError that indicated the list index was out of range.
I checked, double checked and triple checked my code, and I couldn’t see anything wrong with it. I searched online for answers, but nothing I found remotely came close to helping me.
I decided to split up the code into simplest portions and test them bit by bit.
I could split the location data from the first row successfully, getting both the city and state as expected. This led me to suspect that probably there were some entries in the location column that did not have the both the city and state recorded. It made sense, since that would explain why I was getting a list index out of range error. Trying to index the second item would result in that error if it did not exist in the first place.
Now I needed a way to prove this theory.
First I set up a variable to hold the split location data.
| place = df['Location'].apply(lambda x: x.split(', ')) |
Next I wrote the following code to go through that variable and check to see if any entries had just one item. If so, that entry was appended to a list. The second position in that entry was then filled with a null value.
| place = df['Location'].apply(lambda x: x.split(', ')) | |
| stateless = [] | |
| for i in range(len(place)): | |
| if len(place.loc[i]) == 1: | |
| place.loc[i].append(np.nan) | |
| stateless.append(place[i][0]) |
Results show that indeed some entries only had the one item in them.
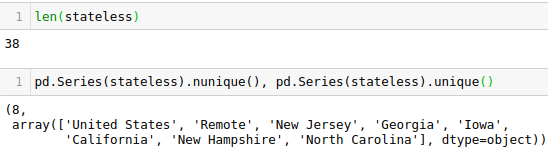
Some of these are actually state names. Looking at the numbers majority were entered as United States and Remote. The states each had just 1 entry (for a total of 6).

I also got to learn some geography. I had seen some country names and wondered if I had done something wrong during the scraping. Turns out, these are all bona fide cities in the US. There is also a city called Location!

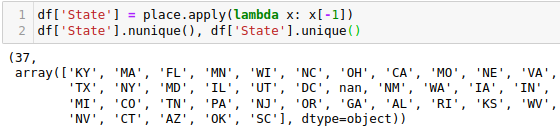
On checking the list of unique states, the output showed that some cities showed up on there.

Looking at one of those locations, it showed that there was an additional location besides city and state.
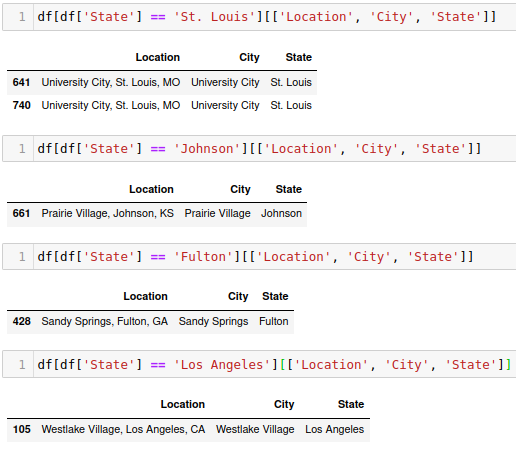
To resolve this, I indexed the state a different way.
The city still showed up wrong, so I need to fix that as well.

I used the code below to get the city column properly filled.
| for i in df.index: | |
| if len(df.loc[i, 'Location'].split(', ')) == 3: | |
| df.loc[i, 'City'] = df.loc[i, 'Location'].split(', ')[1] | |
| elif len(df.loc[i, 'Location'].split(', ')) == 2: | |
| df.loc[i, 'City'] = df.loc[i, 'Location'].split(', ')[0] | |
| else: | |
| df.loc[i, 'City'] = np.nan |
This fixed the problem…

Once the city column was sorted, I went back to deal with the 38 entries that had just 1 item in location. To start, I decided to just do away with the 17 entries with United States, since they comprise less than 1% of the total data. Two of them in the job description showed up as remote positions, but for now I decided to remove even those. In future I will work on ascertaining remote positions based on other fields (such as job description). But for now, I relied only on the location column.
| df = df[df['City'] != 'United States'] |
For the entries with remote, I just copied that over to both state and city.
| df.loc[df['City'] == 'Remote', 'State'] = 'Remote' |
This leaves us with the 6 entries that have only state names in the location column. For these, I just wrote code to extract the state abbreviation, referencing a dataframe of state names whose columns are full state name and abbreviated state name.

First I changed the city name to unknown…
| df.loc[df['State'].isnull(), 'City'] = 'Unknown' |
Then I read in the data with state names (full and abbreviated)
| states = pd.read_csv('temp/us-states.csv', sep = ' - ', engine = 'python', | |
| header = None, names = ['State', 'Abbreviation']) |
Finally the code to populate the state column with the abbreviated state name.
| for i in df.index: | |
| if df.loc[i, 'Location] in list(state['State'].unique()): | |
| state_full = df.loc[i, 'Location'] | |
| state_abbrev = list(states[states['State] == state_full]['Abbreviation'])[0] | |
| df.loc[i, 'State'] = state_abbrev |

Here is a sample of the output from the exercise.

This has been a wonderful experience. Here are some of my takeaways from doing this work:
Lessons Learnt:
This is a marathon. Not a sprint. If it means I dwell on parsing even just one column for a month, then so be it. So long as by the time I am done, I fully understand what it is I need to do and how to do it.
The more I do it, the more I realise just how much I find cleaning data fun! Looking at all the inconsistencies, then figuring out how to resolve those, then having a final dataframe exactly how I want it.
Well, more like previous lesson reinforced… Break the hardest problems into the tiniest possible portions. Solving those portions is usually a very simple thing. Then just build up each step back to the full hard problem. Byte sized chunks. Easier to chew on then eventually swallow!
Feedback/critique is very welcome. Thank you.