Well, a friend asked for help coming up with a solution to automate the processing of Excel spreadsheets a certain way. That was a super interesting problem. I immediately took upon the task of trying to figure it out. I got lost in the process, experiencing a very deep flow state, as it took me about 4 hours to figure out a way.
I was so excited about the solution, that I knew I just had to write about the process of getting to it.
Which leads to the explanation of why I need a brain transplant.
I could not use my friend’s data in the article, for obvious reasons.. I had to come up with fake data to illustrate the path to the solution.
At first I thought I'd use random towns from Kenya, looking at various measures about them (population, number of households, etc).
But...
My brain thought that might not work, since whatever I was to show would not be thaaaat accurate. Even though the plan from get go was to generate make-believe data!
Next option was to use fictional places. I had thought of getting a mix of places from various fictional worlds. While typing them out, the first five locations all ended up being places in Middle Earth. I figured, okay, maybe then we do a Middle Earth themed dataset.
But…
The original problem reared its head. How do I know the data is plausible? So off into another rabbit hole I went, getting varioussources to lend some credibility to the numbers.
And then I ran into a hitch... Part of the data I was coming across had time as a component. Hmm... What problem would that bring? I am glad you asked!
My plan was to have the data cover the last few months leading up to that episode.
But...
Pandas DatetimeIndex gagged on years beyond 2262 (as of the time of writing this article on the 30th of August 2021 A.D. in good ol' regular Earth)! It did throw an error when I asked it to extract the year from a date in 3021. I worked my way backwards by centuries then decades then years until I found that 2262 was the last year it recognized. Anything beyond that resulted in an OutOfBoundsDatetime error
What now?
I decided to ditch the latter years, and instead go back to the earlier years to get some data from that period.
But…
Earlier years meant not having Hobbits in the mix, since none of the source material had info on their numbers before a certain year. And yet you can't have references to Middle Earth without Hobbits in the picture! I mean, they saved the world!
I know, I know! Remember, I told you I need a brain transplant, so give your eyes a break and don't roll them too hard!
What solution did I end up using?
Back to a mix of the various fictional lands, and a mix of beings from each of those lands. In this place, somehow all the various beings co-exist. And in this very modern day and age, thus, no more fumbling with DatetimeIndex's foibles.
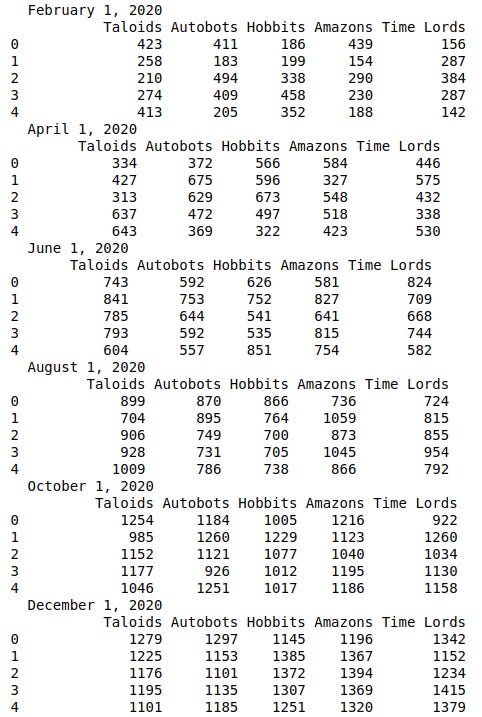
The data I eventually decided to generate is population counts of the various beings in the various worlds taken every second month in the year 2020 (they must be a very wealthy and highly efficient lot to afford a full census every other month spread out over all those worlds). We also have the area in square units, as well as the census ID code for each of those worlds.
Before proceeding, I must add this: A project of this kind involves a lot of twists and turns and dead ends and retracing of steps. And searching. Lots and lots of searching. And looking through documentation. And reading. Which took up the majority of the 4 hours I spent working out the solution.
With that super long preamble out of the way, let's get on with the business at hand and process some Excel files (those are too many mentions of the word super!).
Problem Statement
The task at hand is to transform the spreadsheet from a wide format…
… to a long format.
Solution, 1.0
Read In Data
The first thing I did was import required libraries, then read in the data and display the first few rows.
import pandas as pd
df = pd.read_excel("../data/worlds_census.xlsx",
sheet_name="Wide")
df.head()
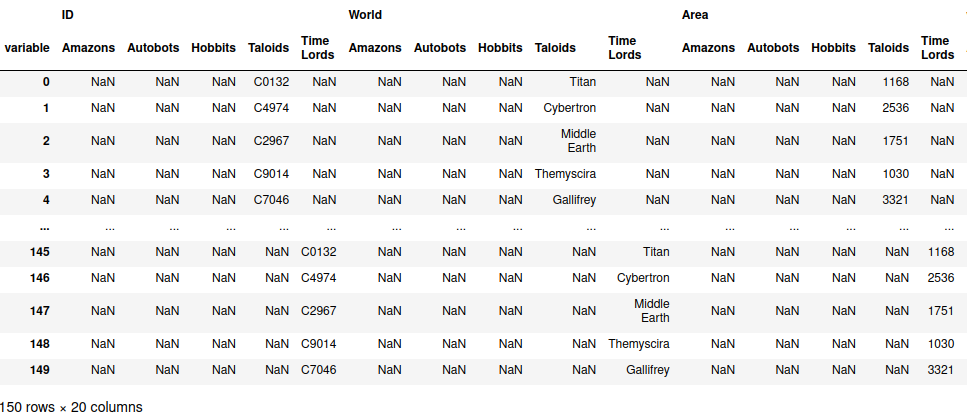
I found out right away that something was amiss as illustrated in the figure below.
The first row of the dataframe was composed of column names. It was not the actual data itself. The original Excel file has a hierarchical index. There are groups of columns (World Info, February 1, 2020, … December 1, 2020). For each group, each column has it’s own name. That group of names is what the above figure shows as the first row.
I needed to read in the data from the Excel file such that the dataframe is shown as a multi-index object. Looking through the Pandas documentation, I found that the read_excel() method has a header parameter that takes in a value that indicates what row to use as the column names. Passing in a list of numbers indicates that the resulting dataframe should be multi-indexed.
I went ahead and did that to see what result I would get.
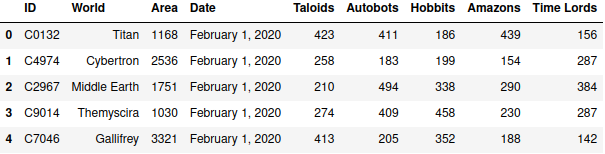
This was more like it. Now I had the first header row from the original Excel file displaying the group names, and the second header row displaying individual column names as expected.
Process Data
When I first had the problem described, my initial impression was that it could be solved by a quick melt operation. The code below resulted in a dataframe that didn’t quite look like what I was aiming for.
Nothing I tried would get me the results I needed. There was just no solution I could find that would give the required output. I even tried melting then unmelting (unpivoting and pivoting), but that just confused things even more.
Before I dug the hole any deeper, I had to just put a stop to all this aimless exploration. Since I knew exactly what the output needed to be, I decided to simplify things and figure it out for just one date. Once that was sorted out, I could then figure out a way to apply it to all 6 dates.
I extracted the data for February 1, 2020 to work with.
df = df[["February 1, 2020"]]
Next, I needed to have the multi-index flattened. To do this, I used the to_records() method to convert the dataframe into a NumPy records array, then convert that back into a dataframe.
df = pd.DataFrame(df.to_records())
I then dropped the index column and renamed the rest of the columns.
Point of note: You need to specify axis="columns", since you are combining columns. The alternative, which is the default, axis="rows", means you are combining rows. That would result in the following output:
Now I needed to move the date to the start of the dataframe, following the same steps as before. The index position of the date column is 3.
date = df[list(df.columns)[3]]
df.drop(["Date"], axis="columns", inplace=True)
df.insert(0, "Date", date)
Finally, I had to transform the date column to be displayed in the desired format, MMM-DD. This was a two step process.
Convert the column data type from object to datetime.
The task was complete! At least for one date. I now had to repeat this for each of the dates in the original dataframe.
Automate Processing
To start the process, I had to first extract the date information from the dataframe. My initial intuition led me to think I could just do a normal column listing (df.columns), then get that information. But that led to this result:
Not what I expected.
Remember, this is a multi-index, so it will return a list of tuples , each composed of the higher level and lower level column names. To access the higher level name of each tuple, I would need to do this:
df.columns[0][0]
Knowing this, what I needed to do was access the first item of each tuple, then record that value. But I needed just one copy of each item. And I also needed to get just the dates, ignoring the World Info group.
The following code generated the result I needed:
dates = []
for i in df.columns:
if i[0] not in dates and not i[0].startswith("World"):
dates.append(i[0])
With this, I could now get a subset of each date period from the original dataframe.
for i in (dates):
print(df[[i]])
The next step was to assign each period’s dataframe to its own variable, perform the date column manipulation, add the initial three columns, then concatenate everything into one final dataframe.
Something that had puzzled me for sometime, and that I finally got to resolve while working on this problem was how to generate a sequence of variables, each having a unique identifier. I needed to get each dataframe generated have a unique identifier.
Enter the globals() method. For details on what it is and how it works, check out this article.
The code below assigns each date’s dataframe to a variable, then creates a list of those dataframes.
df_dates = []
for i, value in enumerate(dates):
globals()["df%s" %i] = df[[value]]
df_dates.append(globals()["df%s" %i])
With all 6 dataframes in place, next I needed to flatten each of them, rename the columns, add the date column, then move the column to the first position. I defined two functions to carry out these operations.
Knowing what we know about listing of column names, I decided to generate a columns_races variable that I used to rename the columns.
column_races = []
for i in list(df.columns):
if i[1] not in column_races and not\
i[0].startswith("World"):
column_races.append(i[1])
Now the code to process the dataframes:
reorganized_dataframes = []
for i, value in enumerate(df_dates):
value = df_flatten(value)
value.columns = column_races
value["Date"] = dates[i]
value = df_organize(value, -1)
reorganized_dataframes.append(value)
Following this, I set up code to concatenate each of the generated dataframes with the three-column dataframe that I had generated from before, df_first_columns.
Once each of the dataframes was set up, I then concatenated all into one final dataframe. I did not specify the axis since the default action of concatenating rows is what I was looking to do.
dataframes_to_concatenate = []
for i, value in enumerate(reorganized_dataframes):
globals()["d%s" %i] = pd.concat([df_first_columns,
reorganized_dataframes[i]],
axis="columns")
dataframes_to_concatenate.append(globals()["d%s" %i])
df_concatenated = pd.concat(dataframes_to_concatenate,
ignore_index=True)
The additional parameter in the command to concatenate, ignore_index=True is needed so as to ensure the final dataframe has a continuous index, as opposed to one that is in chunks from each of the individual dataframes.
The last thing to do was move the date column to the first position, and then format it to the required output. I used the prior defined function df_organize() to move the column.
The solution I just shared is the one I ended up providing to my client. And it worked okay. This was back in mid July 2021. I had always planned to document the process to the solution, but just never got round to it. When I finally did so last week (last week of August 2021), I realised as I was going through the code that there were a number of ways I could have done a better job.
Thus version 2.
The first part of reading in the file remained as is.
The next part of extracting the various categories (World Info and dates) changed drastically, enabling me to cut off quite a bit of code in the process.
I found that the way I was sub-setting the data with double brackets returned a multi-indexed dataframe, which meant the need to flatten it at some point. But if I used just single brackets, I could get the data needed, but without the additional index level. This allowed me to get rid of the code required to flatten the index and rename the columns.
I also found that I could create a list of column names, and use that to extract the various categories in one subsequent for loop instead of the three different for loops I had in version 1.
This version also got rid of the globals() method. I realised I was overthinking in using it. I did not have to generate variable names, since I was appending the dataframes to be concatenated directly to a list. There was no point at which I needed to reference the individual dataframes.
I was able to get rid of a fourth for loop used to do a final concatenation by combining it with the the category extraction for loop. Within that for loop, I rearranged the code to get rid of the need for code to relocate the date column.
The final part of formatting the date column remained unchanged.
Version 2 cut down the lines of code by two thirds, from 42 to 14 lines.
Final Touches
With the main task of solving the primary pain point done, I figured I could add some features to sweeten the solution.
The two features I decided to add were file open and save file dialogue windows. I implemented this using the tkinter library.
import pandas as pd
import tkinter as tk
from tkinter import filedialog as fd
root = tk.Tk()
file = fd.askopenfile()
root.destroy()
if file:
sheetname = input("Please enter the sheet name to use: ")
df = pd.read_excel(file.name,
sheet_name = sheetname,
header=[0, 1])
...
root = tk.Tk()
file = fd.asksaveasfile(mode='w',
initialfile='Untitled.csv',
defaultextension=".csv",
filetypes=[("CSV", "*.csv")])
root.destroy()
if file:
df.to_csv(file, index=False)
file.close()
I also added a prompt asking the user to type in the sheet name to use. Previously I had hard coded this.
I made a separate script that can be called from the command line as well…
Conclusion
A part of me did not want to publish this article initially. I felt as though the version one solution I came up with was not elegant. Or efficient. Or whatever other reason.
After my client sent me a message describing how this solution really helped her carry out her tasks efficiently, stating how she knew that without this code, she may have had to spend a day or two preparing the Excel files for analysis, with the solution I offered her cutting that time down from two days to just under an hour, I knew I just had to publish.
I am aware that as my skills improve with more deliberate practice, a time will come when I shall look back at past solutions and cringe at them. But that is a good thing to anticipate! Because it means that I will have grown!
Not elegant?
Not efficient?
Well, how about Saved Time?
And made someone happy and less stressed?
I can live with that.
If you want to play with the code, you can access it on my github. I welcome any feedback both on this article and the code itself.